The Unsolved Challenges of LLMs as Generalist Web Agents: A Case Study
Abstract
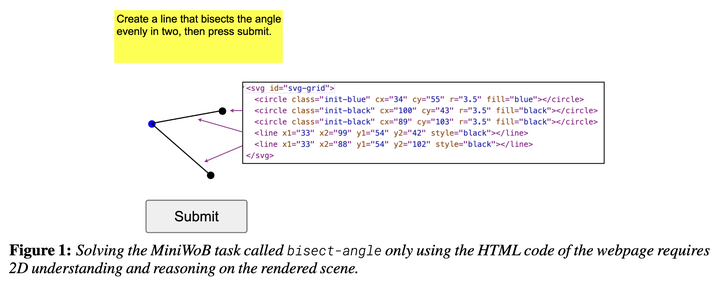
In this work, we investigate the challenges associated with developing goal-driven AI agents capable of performing novel tasks in a web environment using zero-shot learning. Our primary focus is on harnessing the capabilities of large language models (LLMs) as generalist web agents interacting with HTML-based user interfaces (UIs). We evaluate the MiniWoB benchmark and show that it is a suitable yet challenging platform for assessing an agent’s ability to comprehend and solve tasks without prior human demonstrations. Our main contribution encompasses a set of extensive experiments where we compare and contrast various agent design considerations, such as action space, observation space, and the choice of LLM, with the aim of shedding light on the bottlenecks and limitations of LLM-based zero-shot learning in this domain, in order to foster research endeavours in this area. In our empirical analysis, we find that: (1) the effectiveness of the different action spaces are notably dependent on the specific LLM used; (2) open-source LLMs hold their own as competitive generalist web agents when compared to their proprietary counterparts; and (3) using an accessibility-based representation for web pages, despite resulting in some performance loss, emerges as a cost-effective strategy, particularly as web page sizes increase.